Discover more from Latent Space
The AI Engineer newsletter + Top 10 US Tech podcast. Exploring AI UX, Agents, Devtools, Infra, Open Source Models. See https://latent.space/about for highlights from Chris Lattner, Andrej Karpathy, George Hotz, Simon Willison, Emad Mostaque, et al!
Over 31,000 subscribers
The Latent Space crew will be at NeurIPS on Tuesday! Reach out with any parties and papers of interest. We have also been incubating a smol daily AI Newsletter and Latent Space University is making progress.
If ChatGPT was introduced as a low-key research preview in Nov 2022, it’s 1 year anniversary was as high-key as it gets, starting with the first Dev Day (our coverage here) and ending with leadership drama that amounted to “agi delayed four days”.
-
We’re already tired of the nonstop coverage so we’ll refrain, but if you want good 1 year ChatGPT retrospectives we recommend those from our friends at ThursdAI and the AI Breakdown, as well as traditional media like the Verge.
-
A nice paper from NTU Singapore recaps the evolution in open source LLMs:
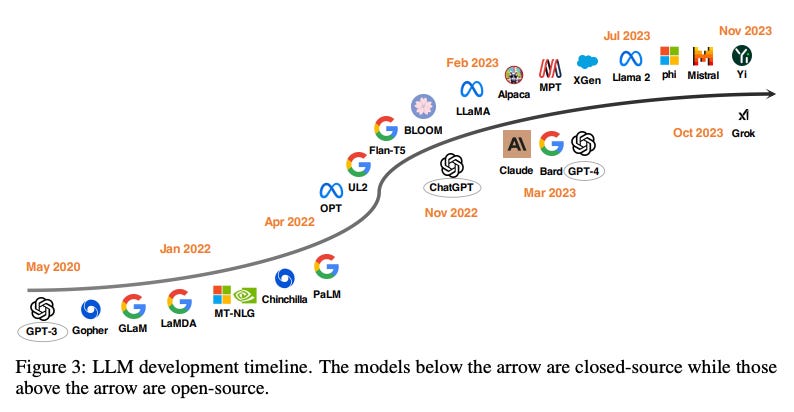
However one underrated perspective on ChatGPT impact we like comes from the slowly rising AI background noise we are all having to contend with on a day-to-day basis, going very rapidly from amusing to alarming.
It is likely that history will look back at Nov 2022 as the last time we were able to easily obtain low-background tokens1:
-
After returning from the Manhattan Project, Willard Libby continued exploring the implications of radioactivity in the atmosphere, inventing radiocarbon dating in 1946, for which he received the 1960 Nobel Prize in Chemistry.
-
Libby immediately recognized that tools which measure very low levels of radioactivity must themselves be low-radioactivity, and that since the Trinity nuclear bomb in 1945, our atmosphere has had2 elevated levels of background radiation, causing high demand for pre-WW2 “low-background” steel for everything from Geiger counters to photonics equipment.
-
We can make a similar analogy for “low-background tokens”.
-
As LLMs became both viable and easily available, the amount of background AI-generated noise rose noticeably in the past year:

-
Elon Musk’s Grok AI, announced Nov 3rd, is among the latest of many LLMs trained post-ChatGPT that now exhibit influence from OpenAI output.

from X. The solution cannot simply be doing a “search and delete of all mentions of OpenAI”, because then you’d end up with a model that doesn’t know what OpenAI is. -
Nov 2023 was also the month we started putting LLMs online – not merely adding Web Search (as was done in Sept), nor updating the knowledge cutoff (first to Jan 2022 then to Apr 2023) – but making live online search an integral part of the experience, with Grok boasting this feature and Perplexity releasing 7b and 70b online LLMs, referencing the FreshLLMs paper, closing the loop for AI consuming AI-created content in ever-faster fashion3.
While rising AI concentrations in our content atmosphere is a concern, we should bear in mind that humans are perfectly capable of spouting industrial quantities of “complete nonsense” as well – this was also the month that Q* mass hysteria swept the AI-content-creator industrial complex, hallucinating days’ and books’ worth of video and essays based on a “leak” of a single letter codename, gleefully egged on by 4chan (We do take some pride in calling out the frontier of Long Inference a few months before it was cool, but not much).
While it may be impossible to screen out AI-generated content in massive datasets, many of us believe that we can still spot AI content in isolated, individual cases, particularly in 1:1 communication. It might be tempting to conclude that higher-bandwidth content, like voice and video, should be even easier to trip our AI spidey senses. However it might be counter-intuitively easier to be more convincing in those form factors, because there is more data that can be learned:
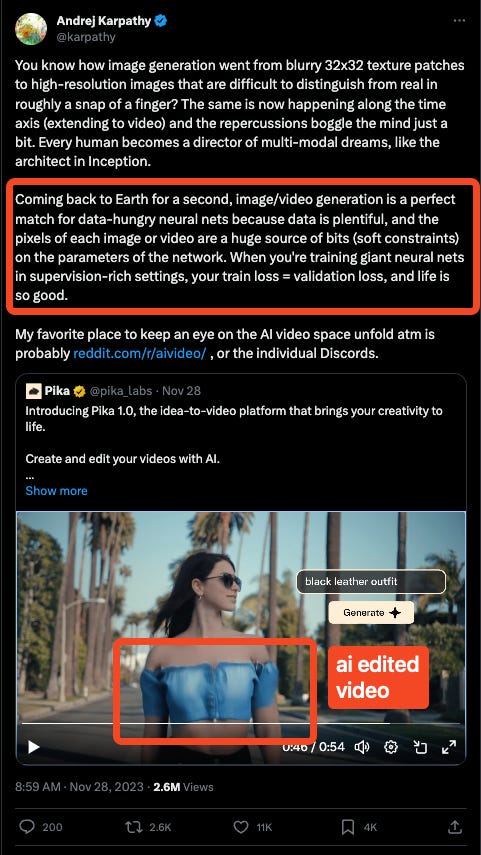
We are not far off from having to worry about background “radiation” in our video and audio content as well.
The last two generative AI trends this month were great illustrations of multimodal AI:
-
Consistency models: Realtime Stable Diffusion was teased in Jan/Feb of this year, but OpenAI only published the Consistency Models paper in March, quickly followed by LCM and LCM-LoRA (discussed in the Latent Space Discord Paper Club). This was the final breakthrough that enabled both Krea and TLDraw to put it in their products, enabled by fal.ai, which is now generating images at 10fps with (upcoming guest!) TLDraw.

Not to be outdone, Stability AI also released SDXL Turbo, which uses a different “Adversarial Diffusion Distillation” technique (paper here, claims to outperform LCMs) to do realtime images, in the same month4.
-
GPT4V Coding: TLDraw was also at the heart of the other big trend of the month, TLDraw’s Make It Real. We cover this in further detail in our upcoming podcast with
, but you can read the synopsis on their Substack.
It was a packed month packed with a lot of drama and we are still recovering from the incredible pace of news. Personally, the conversations about the LLM OS and the June to November evolution from human to systems analogies (aka the Sour Lesson) have been the biggest personal perspective shift.
-
Nov 3 — Beating GPT-4 with Open Source LLMs — with Michael Royzen of Phind
-
Nov 7/8 — AGI is Being Achieved Incrementally (OpenAI DevDay Recap)
-
Full Duration (Live audio, a bit noisy)
-
Cleaned up Audio (Part 2 only: h/t to Klaus Breyer)
-
-
Nov 17 — The State of Silicon and the GPU Poors – with Dylan Patel of SemiAnalysis
-
Nov 18 — The End of OpenAI Hegemony
-
Nov 29 — Notebooks = Chat++ and RAG = RecSys! — with Bryan Bischof of Hex Magic
And last month’s recap if you missed it: The New Kings of Open Source AI (Oct 2023 Recap)
The raw notes from which I draw everything above. You can always see the raw material on Github and of course I can’t see everything, check the other newsletters and podcasters that do.
As always, not everything that we’ve taken note of will make it into this post. To see the entire list of notes for November, check out the ‘AI Notes’ github repo.
We won’t be covering the sama drama in this post. You all know what happened.
-
DevDay (Nov 6) – Opening Keynote is a must watch if you missed it
-
Announced 100m MAU, later revealed to be 14m DAU
-
The notable highlights include the release of Whisper v3, a new generation open-source ASR model, and the progress made in integrating OpenInterpreter. There was buzz around GPT-4 Turbo due to its 128k context, but with mixed reviews(1, 2) regarding its claimed superiority over GPT-4.
-
GPTs: Custom versions of ChatGPT are emerging. These were some notable ones we saw following the announcement. Greg Brockman’s highlight.
-
Typist for enhanced typing assistance
-
and DesignerGPT for web design
-
Simon Willison’s Dejargonizer and “ChatGPT Classic”
-
While they are exciting, jailbreaking them is easy. You can also download uploaded files causing Levels.fyi leaked data (response from founder).
-
Here are prompts for many many other GPTs.
-
-
JSON Mode
-
JSON mode integration has been a topic of interest, with the goal of improving (but not guaranteeing) schema matching.
-
‘functions’ parameter deprecated without much notice.
-
-
Assistants API – open source clone here
-
-
Nov 8: Major outages across ChatGPT and API
-
also
discussing GPT3.5 issues
-
Occasional reports of GPT4 nerfing from biased individuals and on the OpenAI discord
-
-
Nov 14: Sama paused ChatGPT+ signups due to demand – being sold on Ebay
-
Nov 30: Deno SDK
-
2 interesting factoids of upcoming capabilities:
-
improved memory in ChatGPT
-
will be releasing usage tracking based on API key for the OpenAI API
-
-
Claude 2.1: offers an industry-leading 200K token context window (over 500 pages), a 2x decrease in hallucination rates, system prompts, tool use, and updated pricing.
-
https://www.anthropic.com/index/claude-2-1
-
model card
-
$1k test showing declining utilization of the 200k context (“skill issue”)
-
-
Inflection 2
-
https://news.ycombinator.com/item?id=38380377
-
5,000 NVIDIA H100 GPUs in fp8 mixed precision for ~10²⁵ FLOPs. guess is 300b model on 5T tokens
-
slightly better than llama-2
-
1% of rumored GPT5 compute
-
-
Yarn-Mistral-7b-128k:
-
4x more context than GPT-4. Open-source is the new long-context king! This thing can easily fit entire books in a prompt.
-
tweet
-
-
Yi 01 ai 34B released
-
with 100B rumored soon
-
-
Orca 2 https://arxiv.org/abs/2311.11045
-
Orca 1 learns from rich signals, such as explanation traces, allowing it to outperform conventional instruction-tuned models on benchmarks like BigBench Hard and AGIEval.
-
In Orca 2, we continue exploring how improved training signals can enhance smaller LMs’ reasoning abilities.
-
In Orca 2, we teach the model various reasoning techniques (step-by-step, recall then generate, recall-reason-generate, direct answer, etc.).
-
Orca 2 significantly surpasses models of similar size and attains performance levels similar ****or better to those of models 5-10x larger, as assessed on complex tasks that test advanced reasoning abilities in zero-shot settings.
-
-
Amazon Mistral – 32k
-
Qwen-72B and Qwen-1.8B release: 32K context, trained on 3T tokens, <100M MAU commercial license, strong benchmark performance
-
DeepSeek LLM 67B – 4K context, 2T tokens, Apache 2.0 license, strong on code (although DeepSeek Code 33B it benches better)
-
can try at this url
-
-
Elon X.ai Grok
-
Grok-1 is a autoregressive Transformer-based model pre-trained to perform next-token prediction. The model was then fine-tuned using extensive feedbacks from both human and the early Grok-0 models. The initial Grok-1 has a context length of 8,192 tokens and is released in Oct 2023. notes
-
grok vs openchat
-
funny exchange between sama and elon on Grok vs GPTs
-
-
Microsoft Phi-2 at Ignite – 2.7b params, 50% better at math
-
https://x.com/abacaj/status/1724850925741768767?s=20
-
213b tokens
-
some insight from openPhi attempt at replication
-
-
synthetic data from GPT3.5
-
-
Gorilla OpenFunctions
-
open-source function calling model, and are thrilled to present Gorilla OpenFunctions. And yes, we’ve made parallel functions a reality in open-source. tweet
-
but different format than OpenAI
-
-
Stable Video Diffusion
-
Animate anyone – however no code available – but Magic Animate is on Replicate
-
and video LLaVA https://news.ycombinator.com/item?id=38366830
-
and Animate Anyone https://humanaigc.github.io/animate-anyone/
-
and Pika
-
PhotoAI into VideoAI
-
and launching Stability Memberships, a game engine licensing model
-
-
StyleTTS 2: Towards Human-Level Text-to-Speech through Style Diffusion and Adversarial Training with Large Speech Language Models
-
“Eleven-labs quality” – but “Not sure it’s quite up to Eleven Labs quality. But to me, what makes Eleven so cool is that they have a large library of high quality voices that are easy to choose from…. the real special sauce for Eleven is the near instant voice cloning with just a single 5 minute sample, which works shockingly (even spookily) well.”
-
-
Small models: We trained a small transformer (100M params) for basic arithmetic. W. the right training data it nails 12×12 digits multiplication w/o CoT (that’s 10^24 possibilities, so no it’s not memorization. (tweet)
-
HelixNet is a novel Deep Learning architecture consisting of 3 x Mistral-7B LLMs. It has an actor, a critic, and a regenerator.
-
Together AI $102.5m Series A
-
exclusive on Newcomer
-
also announcing Together Inference Engine – 117 tokens per second on Llama-2-70B-Chat and 171 tokens per second on Llama-2-13B-Chat
-
-
Mistral rumored @ 2bn (later confirmed)
-
Voltage Park – New nonprofit backed by crypto billionaire scores AI chips worth $500M – source of Imbue’s “unusually good deal”
-
Factory.ai $5m seed (blog, tweet)
-
Pika Labs $55m seed/Series A (Forbes)
-
Modal labs raised $16m series A with Redpoint
-
Ozone $7m seed for “creating video 10x faster than a human would through context-aware AI.”
good for learning and borrowing code from
-
David Attenborough project (launch, github, arstechnica)
-
Anyscale llm benchmarking standards
-
Replicate – YouTune – finetune image models on yt videos
-
Finetuning
-
gpt evaluator as judge – from llamaindex
-
Learnings from fine-tuning LLM on my Telegram messages
-
-
llama index + pplx api
-
sharing screen with gpt4 vision
-
original
-
swyx’s clone
-
-
insanely-fast-whisper-with-diarisation
-
ggml – tutorial for setting up llama.cpp on AWS instances
-
you can use one of the cheapest 16GB VRAM (NVIDIA T4) instances to serve a quantum Mistral 7B model to multiple clients in parallel with full context.
-
3B LLaMA provisioned for 1 month is $15k? You can run quantum 13B on the g4dn.xlarge instance above for ~$500/month
-
-
LMsys introduced lookahead decoding, a new, exact, and parallel decoding algorithm to accelerate LLM inference. a step above speculative decoding (including Medusa and OSD)
-
react-native ai from Nader Dabit!
-
Full stack framework for building cross-platform mobile AI apps supporting LLM real-time / streaming text and chat UIs, image services and natural language to images with multiple models, and image processing.
-
-
llamafile (HN, Blogpost, simonw writeup):
-
I think my favourite thing about llamafile is what it represents. This is a single binary file which you can download and then use, forever, on (almost) any computer.
-
You don’t need a network connection, and you don’t need to keep track of more than one file.
-
Stick that file on a USB stick and stash it in a drawer as insurance against a future apocalypse. You’ll never be without a language model ever again.
-
-
gpt-fast – a demo codebase for accelerating models with native PyTorch using Torch.compile, quantization, speculative decoding, and tensor parallelism
-
246tok/s – “This is the fastest inference by far I’ve seen.esp without TensorRT
-
-
Open Source Chat with PDF tutorial using pd3f OCR + MistraLite + Prompts
-
VimGPT – Using GPT-4 Vision with Vimium to browse the web
-
Microsoft Ignite and AWS Re:invent announcements
-
Gemini’s absence is deafening
-
-
Elon Musk’s X.ai Grok model was announced but not widely released HN
-
“A unique and fundamental advantage of Grok is that it has real-time knowledge of the world via the X platform.”
-
The engine powering Grok is Grok-1, our frontier LLM, which we developed over the last four months. Grok-1 has gone through many iterations over this span of time. Model Card
-
xAI PromptIDE is an integrated development environment for prompt engineering and interpretability research. https://x.ai/prompt-ide/
-
-
GitHub Copilot GA
Is it just me or is everyone sleeping on the new copilot that just dropped? It works really well in my tests. It does so much more now:
– Plan and write entire projects
– Plan and write notebooks
– Fix bugs, write tests etc.
– Write complex terminal commands pic.twitter.com/4hZ3SraduC— Hamel Husain (@HamelHusain) November 10, 2023
-
workspaceCopilot chatmitchell hashimoto hates it
-
Microsoft Ignite – copilot everything
-
Adept Experiments: https://www.adept.ai/blog/experiments
-
Workflows: Workflows is powered by ACT-2, a model fine-tuned from the Fuyu family and optimized for UI understanding, knowledge worker data comprehension, and action taking.
-
-
Consistency Models
-
krea https://news.ycombinator.com/item?id=38223822
-
live hf space https://huggingface.co/spaces/radames/Real-Time-Latent-Consistency-Model
-
latent consistency and LCM-LoRA are the incremental innovations that spawned the recent work https://huggingface.co/collections/latent-consistency/latent-consistency-model-demos-654e90c52adb0688a0acbe6f
-
So, Generative AI in REAL TIME is here 🔥
Only 4 days have passed and nothing will ever be the same again. All the design tools, all the work processes, EVERYTHING is going to change.
💡 Here is everything you need to know about LCM-LoRA 🧵👇pic.twitter.com/eK3uoxXBlC
— Javi Lopez ⛩️ (@javilopen) November 14, 2023
-
-
TLDraw Make real
-
statecharts and wireframes
-
https://github.com/tldraw/draw-fast
-
small todo app
-
excalidraw response
-
-
Nvidia ChipNeMo, custom LLM trained on Nvidia’s internal data to generate and optimize software and assist human designers for GPU ASIC and Architecture engineers
-
Lindy.ai relaunch
-
Pplx api
-
pplx 7b and 70b online LLMs
-
referencing FreshLLMs: Refreshing Large Language Models with Search Engine Augmentation
-
-
DallE Party – gpt4v and dalle in a loop
-
Visual Anagrams: Generating Multi-View Optical Illusions with Diffusion Models interesting/fun paper and codebase uses Stability AI’s Deepfloyd
-
Our method is conceptually simple. We take an off-the-shelf diffusion model and use it to estimate the noise in different views or transformations of an image. The noise estimates are then aligned by applying the inverse view, and averaged together. This averaged noise estimate is then used to take a diffusion step.
-
-
VectorArt.ai – Use the power of generative AI to create infinitely scalable vector images, logos, icons and illustrations for your website, business or app.
-
Karpathy Intro to LLMs talk
-
with Sarah Chieng notes
-
more thinking about LLM OS
-
PagedAttention, Virtual Context, Speculative Decoding, Register Tokens and other systems programming ideas for LLMs explained
-
-
Bill Gates is back again writing about agents
-
Shanahan, Reynolds, and McDonnell back again in Nature on Role play with large language models. instead of dialogue agent as role-playing a single character, see a dialogue agent as a superposition of simulacra within a multiverse of possible characters.
-
Standard pretraining stack
-
Use flash attention 2, parallel attention and feedforward layers, rotary embeddings, pre-layer norm, and probably 8/3 h multipliers but that doesn’t matter too much. Basically Mistral + parallel layers (they left a free +10% performance on the table). https://x.com/BlancheMinerva/status/1721380386515669209?s=20
-
Train on a large and diverse dataset, something like C4 along plus high quality known components (academic papers, books, code). Ideally you’d scrape these things freshly instead of using Pile / RP. You want to balance clean w/ diverse. Dedupe, but train for 4 epochs (3T+ total)
-
RLHF HISTORY Entangled Preferences: The History and Risks of Reinforcement Learning and Human Feedback
-
https://x.com/natolambert/status/1721250884481634420?s=20
-
-
-
long context methods survey paper
-
https://arxiv.org/pdf/2311.12351.pdf
-
-
MFU calculation
-
Stas Bekman – This study from 2020 publishes the actual achievable TFLOPS in half-precision for the high-end gpus. e.g., 88% for V100, 93% for A100. Showing that A100@BF16’s peak performance is 290 and not 312 TFLOPS. So that means that when we calculate MFU (Model FLOPS Utilization) our reference point shouldn’t be the advertised theoretical TFLOPS, but rather the adjusted achievable TFLOPS.
-
-
other good reads
-
Don’t Build AI Products the Way Everyone Else Is Doing It (builder.io)103 comments
-
Github Universe wrote about The architecture of today’s LLM applications
!https://github.blog/wp-content/uploads/2023/10/LLMapparchitecturediagram.png?resize=4088%2C2148?w=2048
-
Lilian Weng wrote a great survey post on Adversarial Attacks on LLMs (vs images and data extraction)
-
-
Galactica postmortem
-
Notable resignation from Stability AI Audio team, over copyright fair use training
-
beautiful illustrated piece on Stochastic Parrots by the New Yorker
-
Google Switch C 1.6T MoE model (old, but being circulated)
-
https://news.ycombinator.com/item?id=38352794
-
-
$10m Artificial Intelligence Mathematical Olympiad Prize (AI-MO Prize) for AI models that can reason mathematically, leading to the creation of a publicly-shared AI model capable of winning a gold medal in the International Mathematical Olympiad (IMO).
-
List of function calling LLMs
-
llama-cpp-python grammar and on replicate
-
outlines, or jsonformer, instructor
-
glaive function calling v1
-
Gorilla LLM
-
Trelis/Mistral-7B-Instruct-v0.1-function-calling-v2
-
meetkai/functionary-7b-v1.4
-
openhermes2.5 can do it? bc of airoboros
-
-
Humane AI Pin vs Tab Pin comparison
-
actually good defense of standalone vector DBs vs normal DB with vector index
-
meanwhile people keep writing new VectorDBs, like Kagi does
-
This was a VERY fruitful month for memes, and we even got in on a bit of it. But leadership drama memes aside (some of which aged poorly), we have to give the Nov Best AI Meme award to Laundry Buddy (attributable to Jeremy Howard):
and the people voted for “make more” memes
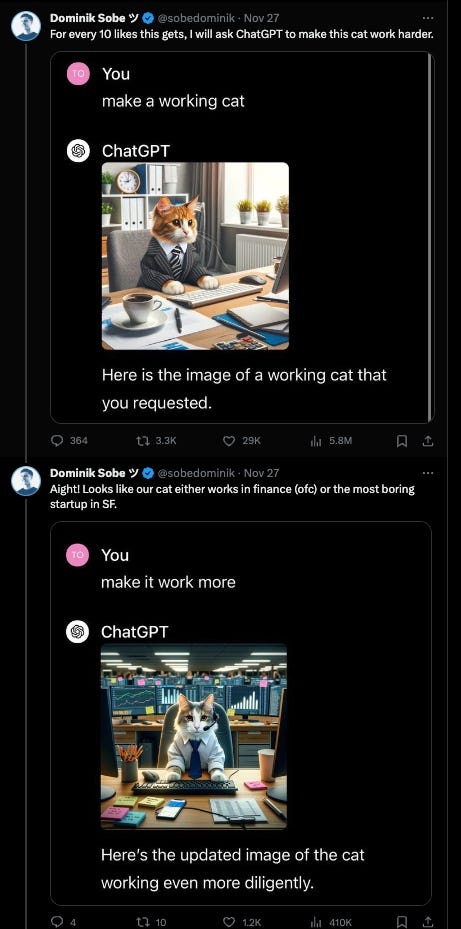
of which we loved the security variant and the muscular croissant variant.
Of course, we can combine memes:

{kind=link}