Making a command out of your wish?
Long-term persistence, real-time interactions remain huge hurdles for AI worlds.
A sample of some of the best-looking Genie 2 worlds Google wants to show off.
Credit:
Google Deepmind
In March, Google showed off its first Genie AI model. After training on thousands of hours of 2D run-and-jump video games, the model could generate halfway-passable, interactive impressions of those games based on generic images or text descriptions.
Nine months later, this week’s reveal of the Genie 2 model expands that idea into the realm of fully 3D worlds, complete with controllable third- or first-person avatars. Google’s announcement talks up Genie 2’s role as a “foundational world model” that can create a fully interactive internal representation of a virtual environment. That could allow AI agents to train themselves in synthetic but realistic environments, Google says, forming an important stepping stone on the way to artificial general intelligence.
But while Genie 2 shows just how much progress Google’s Deepmind team has achieved in the last nine months, the limited public information about the model thus far leaves a lot of questions about how close we are to these foundational model worlds being useful for anything but some short but sweet demos.
How long is your memory?
Much like the original 2D Genie model, Genie 2 starts from a single image or text description and then generates subsequent frames of video based on both the previous frames and fresh input from the user (such as a movement direction or “jump”). Google says it trained on a “large-scale video dataset” to achieve this, but it doesn’t say just how much training data was necessary compared to the 30,000 hours of footage used to train the first Genie.
Short GIF demos on the Google DeepMind promotional page show Genie 2 being used to animate avatars ranging from wooden puppets to intricate robots to a boat on the water. Simple interactions shown in those GIFs demonstrate those avatars busting balloons, climbing ladders, and shooting exploding barrels without any explicit game engine describing those interactions.
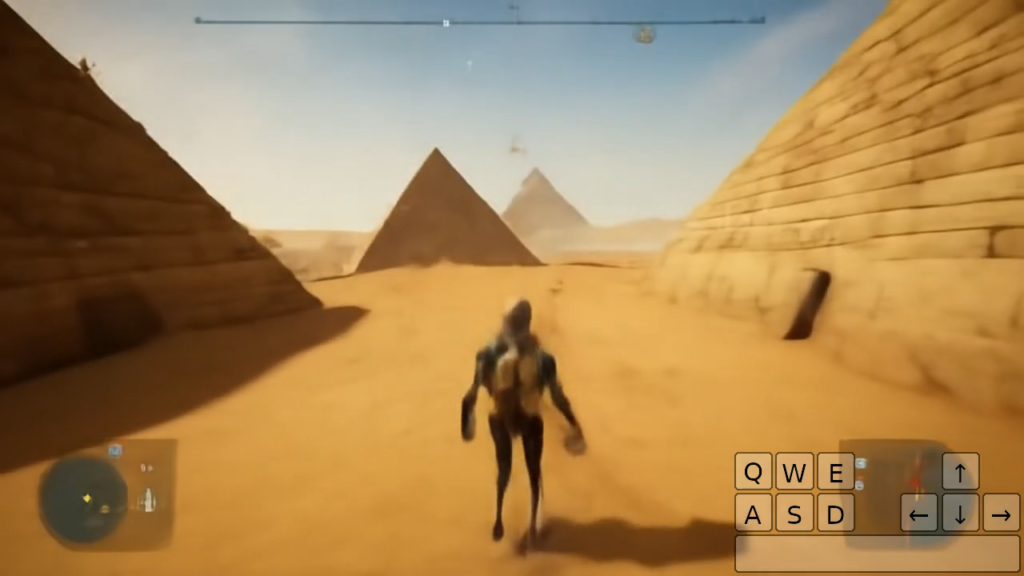
Those Genie 2-generated pyramids will still be there in 30 seconds. But in five minutes?
Credit:
Google Deepmind
Perhaps the biggest advance claimed by Google here is Genie 2’s “long horizon memory.” This feature allows the model to remember parts of the world as they come out of view and then render them accurately as they come back into the frame based on avatar movement. This kind of persistence has proven to be a persistent problem for video generation models like Sora, which OpenAI said in February “do[es] not always yield correct changes in object state” and can develop “incoherencies… in long duration samples.”
The “long horizon” part of “long horizon memory” is perhaps a little overzealous here, though, as Genie 2 only “maintains a consistent world for up to a minute,” with “the majority of examples shown lasting [10 to 20 seconds].” Those are definitely impressive time horizons in the world of AI video consistency, but it’s pretty far from what you’d expect from any other real-time game engine. Imagine entering a town in a Skyrim-style RPG, then coming back five minutes later to find that the game engine had forgotten what that town looks like and generated a completely different town from scratch instead.
What are we prototyping, exactly?
Perhaps for this reason, Google suggests Genie 2 as it stands is less useful for creating a complete game experience and more to “rapidly prototype diverse interactive experiences” or to turn “concept art and drawings… into fully interactive environments.”
The ability to transform static “concept art” into lightly interactive “concept videos” could definitely be useful for visual artists brainstorming ideas for new game worlds. However, these kinds of AI-generated samples might be less useful for prototyping actual game designs that go beyond the visual.
On Bluesky, British game designer Sam Barlow (Silent Hill: Shattered Memories, Her Story) points out how game designers often use a process called whiteboxing to lay out the structure of a game world as simple white boxes well before the artistic vision is set. The idea, he says, is to “prove out and create a gameplay-first version of the game that we can lock so that art can come in and add expensive visuals to the structure. We build in lo-fi because it allows us to focus on these issues and iterate on them cheaply before we are too far gone to correct.”
Generating elaborate visual worlds using a model like Genie 2 before designing that underlying structure feels a bit like putting the cart before the horse. The process almost seems designed to generate generic, “asset flip”-style worlds with AI-generated visuals papered over generic interactions and architecture.
As podcaster Ryan Zhao put it on Bluesky, “The design process has gone wrong when what you need to prototype is ‘what if there was a space.'”
Gotta go fast
When Google revealed the first version of Genie earlier this year, it also released a detailed research paper outlining the specific steps taken behind the scenes to train the model and how that model generated interactive videos. They haven’t done the same for a research paper detailing Genie 2’s process, leaving us guessing at some important details.
One of the most important of these details is model speed. The first Genie model generated its world at roughly one frame per second, a rate that was orders of magnitude slower than would be tolerably playable in real time. For Genie 2, Google only says that “the samples in this blog post are generated by an undistilled base model, to show what is possible. We can play a distilled version in real-time with a reduction in quality of the outputs.”
Reading between the lines, it sounds like the full version of Genie 2 operates at something well below the real-time interactions implied by those flashy GIFs. It’s unclear how much “reduction in quality” is necessary to get a diluted version of the model to real-time controls, but given the lack of examples presented by Google, we have to assume that reduction is significant.
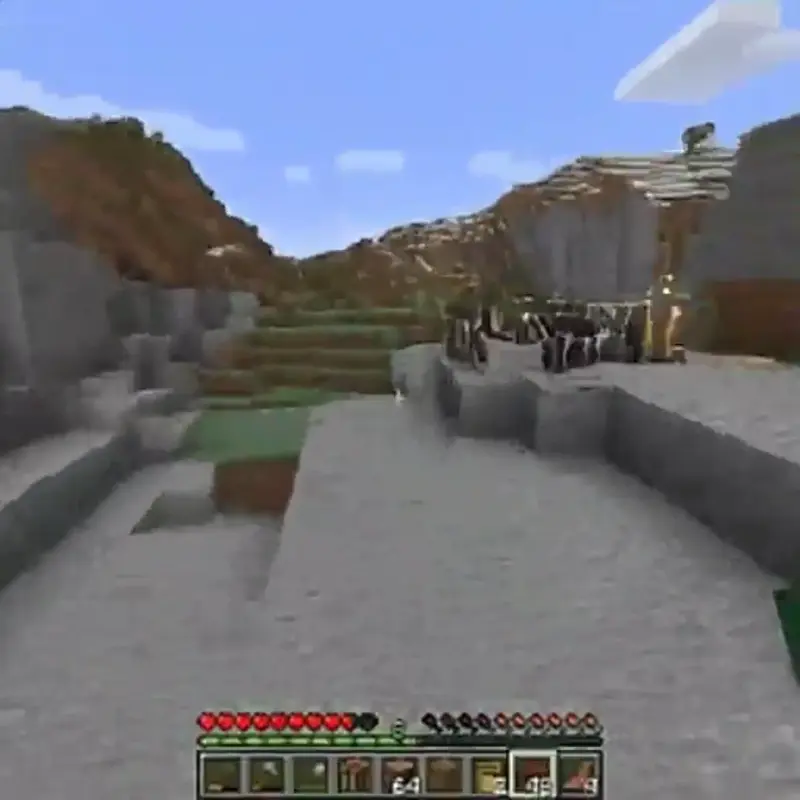
Oasis’ AI-generated Minecraft clone shows great potential, but still has a lot of rough edges, so to speak.
Credit:
Oasis
Real-time, interactive AI video generation isn’t exactly a pipe dream. Earlier this year, AI model maker Decart and hardware maker Etched published the Oasis model, showing off a human-controllable, AI-generated video clone of Minecraft that runs at a full 20 frames per second. However, that 500 million parameter model was trained on millions of hours of footage of a single, relatively simple game, and focused exclusively on the limited set of actions and environmental designs inherent to that game.
When Oasis launched, its creators fully admitted the model “struggles with domain generalization,” showing how “realistic” starting scenes had to be reduced to simplistic Minecraft blocks to achieve good results. And even with those limitations, it’s not hard to find footage of Oasis degenerating into horrifying nightmare fuel after just a few minutes of play.

What started as a realistic-looking soldier in this Genie 2 demo degenerates into this blobby mess just seconds later.
Credit:
Google Deepmind
We can already see similar signs of degeneration in the extremely short GIFs shared by the Genie team, such as an avatar’s dream-like fuzz during high-speed movement or NPCs that quickly fade into undifferentiated blobs at a short distance. That’s not a great sign for a model whose “long memory horizon” is supposed to be a key feature.
A learning crèche for other AI agents?

From this image, Genie 2 could generate a useful training environment for an AI agent and a simple “pick a door” task.
Credit:
Google Deepmind
Genie 2 seems to be using individual game frames as the basis for the animations in its model. But it also seems able to infer some basic information about the objects in those frames and craft interactions with those objects in the way a game engine might.
Google’s blog post shows how a SIMA agent inserted into a Genie 2 scene can follow simple instructions like “enter the red door” or “enter the blue door,” controlling the avatar via simple keyboard and mouse inputs. That could potentially make Genie 2 environment a great test bed for AI agents in various synthetic worlds.
Google claims rather grandiosely that Genie 2 puts it on “the path to solving a structural problem of training embodied agents safely while achieving the breadth and generality required to progress towards [artificial general intelligence].” Whether or not that ends up being true, recent research shows that agent learning gained from foundational models can be effectively applied to real-world robotics.
Using this kind of AI model to create worlds for other AI models to learn in might be the ultimate use case for this kind of technology. But when it comes to the dream of an AI model that can create generic 3D worlds that a human player could explore in real time, we might not be as close as it seems.

Kyle Orland has been the Senior Gaming Editor at Ars Technica since 2012, writing primarily about the business, tech, and culture behind video games. He has journalism and computer science degrees from University of Maryland. He once wrote a whole book about Minesweeper.
52 Comments

{kind=link}